Demografía empresarial de España
Objetivo
El objetivo es obtener los datos sobre la demografía (constitución, disolución o ampliación de capital) empresarial de España por provincias. Para ello utilizaremos como fuente de datos el Instituto Nacional de Estadística (INE) y más concretamente accederemos a los datos a través de su API.
Desarrollo
Para el desarrollo de este artículo ha sido necesario el acceso a los datos a través de la API del INE. Debería ser una tarea sencilla, pero conseguir acceder a los datos necesarios no ha sido una tarea sencilla. Para conocer mejor cómo utilizar la API del INE se ha seguido este tutorial de Exopotamia.
Además, para obtener las URLs de los JSON necesarios para obtener los datos de la demografía empresarial de España es necesario acceder a este generador de URLs del INE.
Resumen de los pasos:
- Paso 1: Obtener el código del INE para los datos demográficos
- Paso 2: Obtener los datos del INE
- Paso 3: Realizar tareas de limpieza de los datos
- Paso 4: Creación del dataframe con los datos extraídos previamente
- Paso 5: Creación del dataframe agregado
Paso 1: Obtener el código del INE para los datos demográficos
El primer paso es obtener el código del INE para los datos de empresas constituidas, disueltas o que aumentan capital. Para ello tenemos que entrar en la web de generación de URLs. A continuación se muestra cómo obtener dichos códigos.
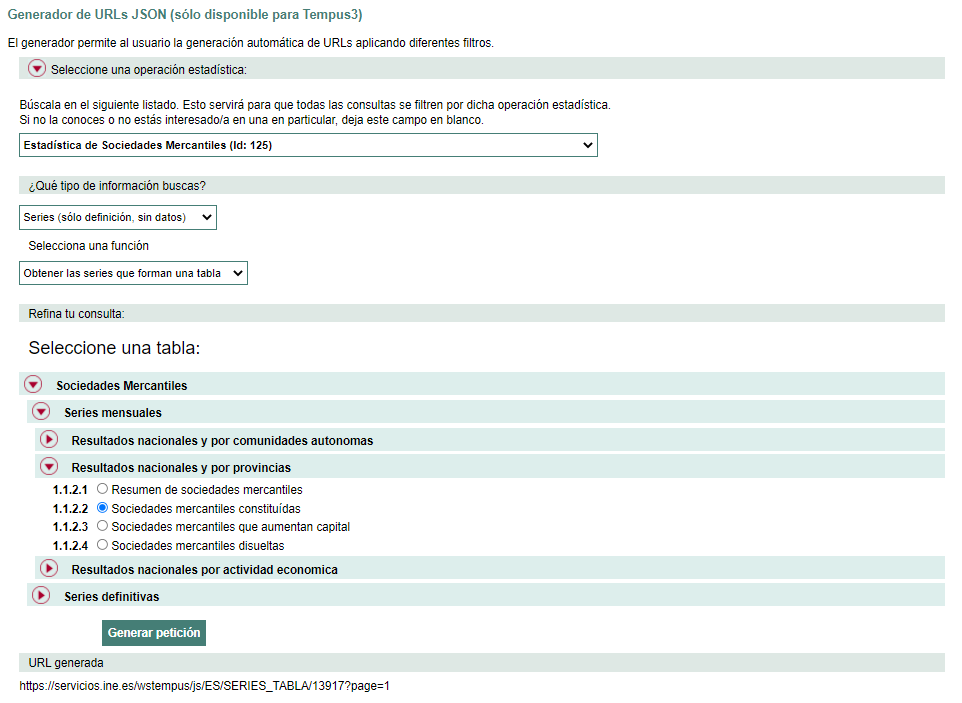
El data a extraer el el código de 4-5 cifras al final de la URL generada. Ver la última fila de la imagen anterior. Por lo tanto el código para obtener los datos por provincias de las sociedades mercantiles constituidas sería el «13917». Este mismo ejercicio habría que hacerlo para el resto de categorías. Con estos datos, generaríamos un diccionario.
codigoINE_empresas = {
"Constituidas" : 13917,
"Aumento de Capital" : 13922,
"Disueltas" : 13923
}
num_datos = 50000
url_plantilla = 'http://servicios.ine.es/wstempus/js/ES/DATOS_SERIE/{codigo}?nult={num_datos}'Paso 2: Obtener los datos del INE
El siguiente paso será hacer la llamada al INE con los códigos obtenidos. Los datos se almacenarán en un dataframe.
for tipo in codigoINE_empresas:
main_url_INE_Estructura_Datos = "https://servicios.ine.es/wstempus/js/ES/SERIES_TABLA/" + str(codigoINE_empresas[tipo]) + "?page=1"
INE_Estructura_Datos = requests.get(main_url_INE_Estructura_Datos).json()
df_INE_Estructura_Datos_Empresas = pd.DataFrame.from_dict(INE_Estructura_Datos)Paso 3: Realizar tareas de limpieza de los datos
Como siempre, los datos no suelen estar como nos gustaría. Por lo que debemos hacer una trabajo de limpieza y ordenación. En este caso, dividimos un campo (Nombre) en varios campos (Nombre, Actividad, Tipo Empresa y Dato) y eliminamos ciertas filas que no nos interesan. Finalmente seleccionamos únicamente aquellas columnas que son de nuestro interés.
df_INE_Estructura_Datos_Empresas["Nombre"] = df_INE_Estructura_Datos_Empresas["Nombre"].str.replace("S. Comanditarias y S. Colectivas", "Sociedades Comanditarias y Sociedades Colectivas")
df_INE_Estructura_Datos_Empresas["Nombre"] = df_INE_Estructura_Datos_Empresas["Nombre"].str.strip()
new = df_INE_Estructura_Datos_Empresas["Nombre"].str.split('.')
if tipo == "Disueltas":
df_INE_Estructura_Datos_Empresas["Nombre"] = new.map(lambda x: x[0])
df_INE_Estructura_Datos_Empresas["Actividad"] = new.map(lambda x: x[2])
df_INE_Estructura_Datos_Empresas["Tipo Empresa"] = new.map(lambda x: x[1])
df_INE_Estructura_Datos_Empresas["Dato"] = new.map(lambda x: x[3])
else :
df_INE_Estructura_Datos_Empresas["Nombre"] = new.map(lambda x: x[0])
df_INE_Estructura_Datos_Empresas["Actividad"] = new.map(lambda x: x[1])
df_INE_Estructura_Datos_Empresas["Tipo Empresa"] = new.map(lambda x: x[2])
df_INE_Estructura_Datos_Empresas["Dato"] = new.map(lambda x: x[3])
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Sociedades Constituídas"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Aumento de Capital"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Total"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Total Nacional"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Voluntaria"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Por fusión"].index, inplace=True)
df_INE_Estructura_Datos_Empresas.drop(df_INE_Estructura_Datos_Empresas[df_INE_Estructura_Datos_Empresas.Nombre == "Otras"].index, inplace=True)
df_INE_Estructura_Datos_Empresas = df_INE_Estructura_Datos_Empresas[["Id","COD","Nombre","Actividad","Tipo Empresa", "Dato"]]Paso 4: Creación del dataframe con los datos extraídos previamente
El siguiente paso consiste en la creación del dataframe adecuado a nuestras necesidades. Para ello crearemos un multindex dataframe para que después el acceso a los datos sea más intuitivo y sencillo. Además, en el caso de la fecha, también hacemos una modificación (sumarle una hora) para que la fecha correspondiente al dato sea la correcta.
for index, provincia in df_INE_Estructura_Datos_Empresas.iterrows():
codigo = provincia["COD"]
url_datos = url_plantilla.format(codigo=codigo, num_datos=num_datos)
df_empresas_ = pd.DataFrame.from_dict(requests.get(url_datos).json()["Data"])[["Anyo","Fecha","Valor"]].rename(columns={"Anyo": "Año", "Fecha": "Fecha", "Valor": provincia["Dato"].strip()})
df_empresas_["Fecha"] = pd.to_datetime(df_empresas_["Fecha"], unit='ms')
df_empresas_["Fecha"] = df_empresas_["Fecha"].map(lambda x: x + hours_added)
df_empresas_['Mes'] = df_empresas_['Fecha'].dt.month
df_empresas_ = df_empresas_[["Año", "Mes", provincia["Dato"].strip()]]
df_empresas_ = df_empresas_.set_index(["Año", "Mes"])
df_empresas_.columns = pd.MultiIndex.from_product([[provincia["Nombre"].strip()], [provincia["Actividad"].strip()], [provincia["Tipo Empresa"].strip()], df_empresas_.columns], names=["Provincia", "Actividad", "Tipo de Empresa", "Dato"])
df_empresas = pd.concat([df_empresas, df_empresas_], axis=1)
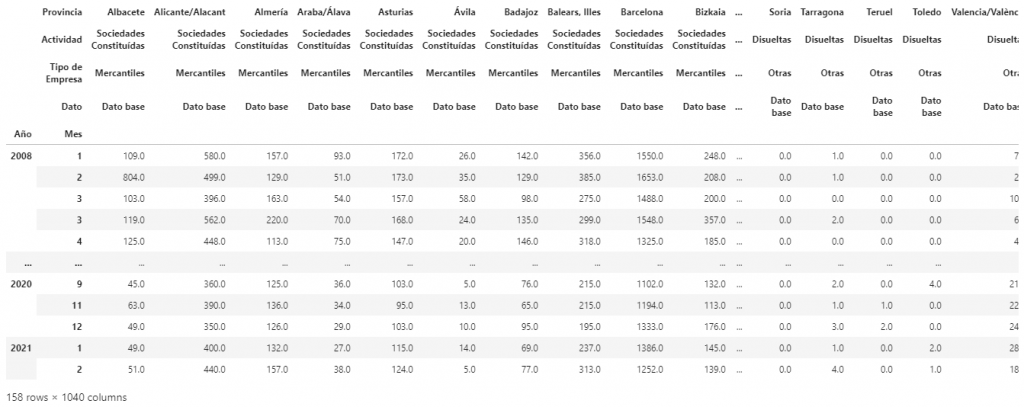
El resultado del anterior script es el siguiente dataframe. Como se puede observar, los índices de columnas «Provincia«, «Actividad» y «Tipo de Empresa» se podrías agregar. Eso es lo que haremos en el siguiente paso.
Paso 5: Creación del dataframe agregado
Gracias a la función «groupby» generaremos agrupaciones que después concatenaremos para crear un nuevo dataframe en la que el acceso a la información sea sencillo y visualmente intuitivo.
provincias = list(df_empresas.columns.levels[0])
df_empresas = df_empresas.groupby(level = 0, axis = 1)
df_situacion_empresas = pd.DataFrame(columns=[])
for pro in provincias:
df_empresas2 = df_empresas.get_group(pro)
df_situacion_empresas = pd.concat([df_situacion_empresas, df_empresas2], axis=1)Resultado
El resultado final de este artículo es un dataframe visualmente intuitivo y que permite el fácil acceso a los datos.
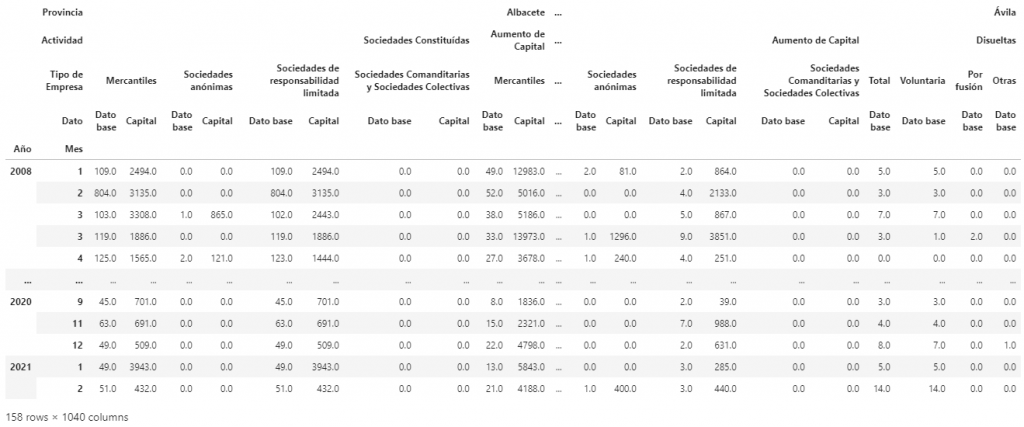
De esta forma se podría acceder a la información deseada de la siguiente forma:
display(df_situacion_empresas[df_situacion_empresas.index.get_level_values("Mes") == 1]["Bizkaia"]["Sociedades Constituídas"]["Mercantiles"])Líneas futuras
En este prototipo quedarían pendientes las siguientes tareas:
- Actualizar los datos mensualmente y de forma automática.
- Crear un dashboard para por ejemplo mostrar la demografía empresarial de Euskadi.
- Cotejar esos datos con los del registro mercantil o con base de datos tipo SABI.