Estadísticas del tráfico aéreo de los aeropuertos de España
Objetivo
El objetivo es realizar un seguimiento mensual de la evolución del tráfico aéreo (pasajeros, operaciones y carga) de los aeropuertos de España o en un aeropuerto en concreto. Para ello, será necesario extraer los datos de los diferentes ficheros MS-Excel mensuales ofrecidos por AENA.
Ver código completo del proyecto en GitHub AENA
Desarrollo
A continuación se describe el proceso realizado para obtener la información del tráfico aéreo (pasajeros, operaciones y carga) de los aeropuertos de España. Como en toda fuente de información histórica, siempre hay estructuras de datos que han cambiado a lo largo del tiempo. Por eso hay que tener en cuenta las siguientes consideraciones previas:
- A lo largo del tiempo han surgido nuevos aeropuertos y en algunos casos, los aeropuertos existentes han cambiado su denominación, tomando diferentes nombre. Un ejemplo de esto último es el aeropuerto de Madrid (MAD) denominándose como «Madrid-Barajas», «Madrid» o el actual «Adolfo Suárez Madrid-Barajas».
- La estructura de los ficheros MS-Excel ha cambiado a lo largo del tiempo. Concretamente para el periodo 2004-2021, la estructura ha cambiado dos veces, en el 2009 y en marzo de 2021.
Resumen de los pasos:
- Paso 1: Obtener denominaciones de los aeropuertos
- Paso 2: Actualizar denominaciones de los aeropuertos
- Paso 3: Obtener información del tráfico aéreo de ficheros MS-Excel
- Paso 4: Actualizar los datos mensualmente
Paso 1: Obtener denominaciones de los aeropuertos
La primera tarea a realizar es obtener las denominaciones pasadas y actuales de los aeropuertos. En un primer momento ha sido una tarea manual que después se actualiza de forma automática. Se ha creado un diccionario en Python en el que para cada código IATA se le asigna su nombre oficial («nombre») y sus otras denominaciones («otros»).
aeropuertos = {}
aeropuertos["MAD"] = {}
aeropuertos["MAD"]["Nombre"] = "ADOLFO SUÁREZ MADRID-BARAJAS"
aeropuertos["MAD"]["Otros"] = ["ADOLFO SUAREZ MADRID-BARAJAS", "MADRID-BARAJAS"]
...Una vez creado el diccionario, generaremos un fichero JSON que almacene dicha información.
import json
with open('AENA_IATA_aeropuertos.json', 'w') as file:
json.dump(aeropuertos, file)Ver código completo en GitHub (AENA_IATA_aeropuertos.ipynb)
Paso 2: Actualizar denominaciones de los aeropuertos
El paso anterior únicamente se realizará una vez. Posteriormente necesitaremos actualizar mensualmente las denominaciones de los aeropuertos. En general, debería ser suficiente a través del «scraping» de la lista oficial de aeropuertos de España.
Primeramente nuestro actualizador de denominaciones de aeropuertos, cargará el fichero JSON generado previamente…
url_AENA_IATA_aeropuertos = "AENA_IATA_aeropuertos.json"
with urllib.request.urlopen(url_AENA_IATA_aeropuertos) as url:
aeropuertos = json.loads(url.read().decode())Posteriormente, tendremos que acceder a la web oficial de AENA en la que se muestra un listado de todos los aeropuertos de España y analizar si ha habido cambios. Cambios en las denominaciones para los códigos IATA ya disponibles, o bien nuevos aeropuertos con códigos IATA no disponibles en nuestro fichero JSON.
url = "http://www.aena.es/es/aerolineas/red-aeropuertos.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
contenido = soup.find_all("div", {"class": "datos_interes"})
has_changed = False
if len(contenido) == 2 :
div_aeropuertos = contenido[1]
a_aeropuertos = div_aeropuertos.findAll("a")
for a_aeropuerto in a_aeropuertos:
sep = '\((.*?)\)'
nombre = re.split(sep,a_aeropuerto.text,1)[0].strip().upper()
codigo_IATA = re.split(sep,a_aeropuerto.text,1)[1].strip()
if codigo_IATA in aeropuertos:
otros_nombres = []
if "Otros" in aeropuertos[codigo_IATA]:
otros_nombres = aeropuertos[codigo_IATA]["Otros"]
if (nombre != aeropuertos[codigo_IATA]["Nombre"]) and (nombre not in otros_nombres):
print("Nombre del aeropuerto nuevo <" + str(nombre) + "> sobre un código IATA existente.")
#Añadimos el nombre del aeropuerto como nombre principal y pasamos el nombre principal antiguo como otro nombre
if "Otros" in aeropuertos[codigo_IATA]:
aeropuertos[codigo_IATA]["Otros"].append(aeropuertos[codigo_IATA]["Nombre"])
else:
aeropuertos[codigo_IATA]["Otros"] = []
aeropuertos[codigo_IATA]["Otros"].append(aeropuertos[codigo_IATA]["Nombre"])
aeropuertos[codigo_IATA]["Nombre"] = nombre
has_changed = True
else:
print("El aeropuerto " + str(nombre) + " no existe. Se añade a la base de datos.")
aeropuertos[codigo_IATA] = {}
aeropuertos[codigo_IATA]["Nombre"] = nombre
has_changed = TrueEl script anterior actualiza el diccionario de los aeropuertos y notifica, a través de la variable «has_changed» si ha habido modificaciones en el diccionario. Si ha habido notificaciones en el diccionario de aeropuertos, entonces se realizará una copia de seguridad de la versión anterior del fichero JSON (incluyendo la fecha en la que pasa a ser obsoleta) y crea un nuevo fichero JSON con el diccionario actualizado.
if has_changed:
print("Actualizar el fichero JSON")
today = datetime.today().strftime('%Y-%m-%d')
os.rename(r'AENA_IATA_aeropuertos.json',r'AENA_IATA_aeropuertos_" + str(today) + ".json')
with open('AENA_IATA_aeropuertos.json', 'w') as file:
json.dump(aeropuertos, file)
else:
print("No hay que actualizar el fichero JSON")Ver código completo en GitHub (AENA_update_IATA_aeropuertos.ipynb)
Paso 3: Obtener información del tráfico aéreo de ficheros MS-Excel
Paso 3.1: Obtener diccionario de aeropuertos
El objetivo de este paso es obtener un diccionario de aeropuertos en el que la clave sea la denominación del aeropuerto (la denominación oficial y el resto de denominaciones) y que el valor sea el código IATA. Es decir, necesitamos crear un diccionario «opuesto» al generado en pasos anteriores.
...
with open('AENA_IATA_aeropuertos.json') as f:
aeropuertos = json.load(f)
for aero_key, aero_value in aeropuertos.items():
aeropuertos_[aero_value["Nombre"]] = aero_key
if "Otros" in aero_value.keys():
for item in aero_value["Otros"]:
aeropuertos_[str(item)] = aero_keyPaso 3.2: Obtener las URLs de los ficheros MS-Excel mensuales
El siguiente paso es obtener las URLs de los ficheros MS-Excel mensuales que AENA proporciona en su web. De esta manera, tendríamos los enlaces estructurados en un Dataframe de Python con estructura de «Año / Mes».
links_excels_AENA = {}
for ano in range(ano_inicio,ano_actual+1):
url = "https://wwwssl.aena.es/csee/Satellite?SiteName=Estadisticas&anyo=" + str(ano) + "&c=Page&cid=1144247795704&pagename=Estadisticas%2FEstadisticas&periodoInforme=Mensual"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
contenido = soup.find_all("td", {"class": "link2"})
if len(contenido) > 0:
for elemento in contenido:
el = elemento.findAll("a", {"class": "link2"})
if ".xls" in el[0]['href']:
mes_ano = el[0].text.strip().partition(" ")
mes = mes_ano[0]
ano = int(mes_ano[-1])
link = main_url + el[0]['href']
if ano in links_excels_AENA:
links_excels_AENA[ano][mes] = link
else :
links_excels_AENA[ano] = {}
links_excels_AENA[ano][mes] = linkPaso 3.3: Preparar los dataframes donde se almacenará la información.
El resultado de este paso serán tres dataframes (df_AENA_pasajeros, df_AENA_operaciones y df_AENA_mercancias) donde se almacenará la información sobre pasajeros, operaciones y mercancías respectivamente.
index = []
for ano in links_excels_AENA:
for mes in links_excels_AENA[ano]:
tupla = (ano, mes)
index.append(tupla)
df_index = pd.MultiIndex.from_tuples(index, names=('Año', 'Mes'))
df_AENA_pasajeros = pd.DataFrame(columns=[], index=df_index)
df_AENA_operaciones = pd.DataFrame(columns=[], index=df_index)
df_AENA_mercancias = pd.DataFrame(columns=[], index=df_index)Paso 3.4: Extraer la información de los ficheros MS-Excel
Como se ha comentado al inicio de este artículo, AENA ha realizado dos cambios en la forma en la que estructura sus ficheros de datos (en 2009 y en Marzo de 2021). Por lo que nuestro script tendrá que realizar diferentes lecturas del fichero MS-Excel dependiendo de la fecha del documento.
if ano < 2009:
df = pd.read_excel(filename, sheet_name=hoja_seleccionada, skiprows=[0,1,2,3,4,5], usecols=[1,2,5,6,9,10])
else:
if (ano >= 2009) and (ano <2021):
#print(hoja_seleccionada)
df = pd.read_excel(filename, sheet_name=hoja_seleccionada, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
else:
if (ano == 2021) and ((mes == "Enero") or (mes == "Febrero"):
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
else :
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,3,7,8,12,13])Y finalmente crearemos los dataframes… En el siguiente código se muestra únicamente el extracto de código para crear el dataframe de viajeros.
df_pasajeros = df[df.columns[0:2]].copy()
df_pasajeros.index.name = 'Aeropuerto'
df_pasajeros = df_pasajeros[df_pasajeros.index.notnull()]
for index, row in df_pasajeros.iterrows():
index = index.strip()
if (index in aeropuertos_.keys()):
if type(row.iloc[0]) == numpy.float64:
valor = row.iloc[0].astype(int)
if type(row.iloc[0]) == float:
valor = int(row.iloc[0].astype(int))
if type(row.iloc[0]) == str:
valor = 0
df_AENA_pasajeros.loc[(ano,mes),aeropuertos_[index]] = row.iloc[0]Paso 3.5: Almacenar resultado
El resultado de los anteriores pasos genera un dataframe. Esta estructura de datos puede ser almacenada (serializada) gracias al módulo Pickle. Esta forma de almacenar en fichero (serializar un objeto de Python) es una forma sencilla de poder posteriormente reutilizarla para el análisis de dicha información.
pd.to_pickle(df_AENA_pasajeros, "./raw_df_AENA_pasajeros.pkl")
pd.to_pickle(df_AENA_operaciones, "./raw_df_AENA_operaciones.pkl")
pd.to_pickle(df_AENA_mercancias, "./raw_df_AENA_mercancias.pkl")Ver código completo en GitHub (AENA_scraping.ipynb)
Paso 4: Actualizar los datos mensualmente
Una vez realizado un primer scraping de la web de AENA, posteriormente únicamente habría que actualizar los datos de forma periódica (mensualmente). Por lo tanto, en este apartado describiremos cómo realizar el actualizador de los datos de AENA.
Paso 4.1: Obtener los datos previos
El primer paso será obtener (deserializar) los dataframes almacenados (serializados) previamente.
df_AENA_pasajeros = pd.read_pickle("./raw_df_AENA_pasajeros.pkl")
df_AENA_operaciones = pd.read_pickle("./raw_df_AENA_operaciones.pkl")
df_AENA_mercancias = pd.read_pickle("./raw_df_AENA_mercancias.pkl")Paso 4.2: Definir los meses de los que obtener los datos
El siguiente paso será obtener la última fecha (año y mes) de datos disponibles en los dataframes para así obtener los datos desde dicha fecha hasta la actualidad.
fecha_datos = df_AENA_pasajeros.index.to_list()
ultimo_ano = fecha_datos[-1][0]
ultimo_mes = fecha_datos[-1][1]
now = datetime.datetime.now()
ano_actual = now.year
mes_actual = now.month
if ultimo_mes == "Diciembre":
ano_ = ultimo_ano + 1
else :
ano_ = ultimo_anoPaso 4.3: Obtener los datos y agregarlos a los dataframes
El siguiente paso, y más importante, será obtener los datos de los diferentes ficheros MS-Excel y agregarlos a los dataframes y existentes. Aquí un extracto de dicho script.
if len(contenido) > 0:
for elemento in contenido:
el = elemento.findAll("a", {"class": "link2"})
if ".xls" in el[0]['href']:
mes_ano = el[0].text.strip().partition(" ")
mes = mes_ano[0]
ano = int(mes_ano[-1])
if (ano,mes) not in fecha_datos:
#obtener datos y agregarlos al dataframe
link = main_url + el[0]['href']
file = requests.get(link)
filename = 'aena_temp.xls'
open(filename, 'wb').write(file.content)
Workbook = xl.open_workbook(filename)
sheets = Workbook.sheet_names()
hoja_seleccionada = ""
for sheet in sheets:
if ("TRÁFICO" in sheet) or ("TRAFICO" in sheet):
hoja_seleccionada = sheet
if (ano < 2009):
df = pd.read_excel(filename, sheet_name=hoja_seleccionada, skiprows=[0,1,2,3,4,5], usecols=[1,2,5,6,9,10])
elif (ano == 2009):
df = pd.read_excel(filename, sheet_name=hoja_seleccionada, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
elif (ano > 2010) and (ano < 2021):
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
elif (ano == 2021) and (mes == "Enero"):
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
elif (ano == 2021) and (mes == "Febrero"):
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,4,7,8,11,12])
else:
df = pd.read_excel(filename, skiprows=[1,2,3,4,5,6,7,8], usecols=[2,3,7,8,12,13])
df_pasajeros = df[df.columns[0:2]].copy()
df_pasajeros = df_pasajeros.set_index(df_pasajeros.columns[0])
df_operaciones = df[df.columns[2:4]].copy()
df_operaciones = df_operaciones.set_index(df_operaciones.columns[0])
df_mercancias = df[df.columns[4:6]].copy()
df_mercancias = df_mercancias.set_index(df_mercancias.columns[0])
df_pasajeros.index.name = 'Aeropuerto'
df_operaciones.index.name = 'Aeropuerto'
df_mercancias.index.name = 'Aeropuerto'
df_pasajeros = df_pasajeros[df_pasajeros.index.notnull()]
df_operaciones = df_operaciones[df_operaciones.index.notnull()]
df_mercancias = df_mercancias[df_mercancias.index.notnull()]
for index, row in df_pasajeros.iterrows():
index = index.strip()
if (index in aeropuertos_.keys()):
if type(row.iloc[0]) == numpy.float64:
valor = row.iloc[0].astype(int)
if type(row.iloc[0]) == float:
valor = int(row.iloc[0].astype(int))
if type(row.iloc[0]) == str:
valor = 0
df_AENA_pasajeros.loc[(ano,mes),aeropuertos_[index]] = row.iloc[0]
has_changed = TruePaso 4.4: Almacenar los cambios en un nuevo dataframe
Al igual que en un paso anterior, el último paso será eliminar los ficheros temporales creados y almacenar (serializar) el dataframe.
if has_changed:
pd.to_pickle(df_AENA_pasajeros, "./raw_df_AENA_pasajeros.pkl")
pd.to_pickle(df_AENA_operaciones, "./raw_df_AENA_operaciones.pkl")
pd.to_pickle(df_AENA_mercancias, "./raw_df_AENA_mercancias.pkl")
os.remove("aena_temp.xls")Ver código completo en GitHub (AENA_update_dataframes.ipynb)
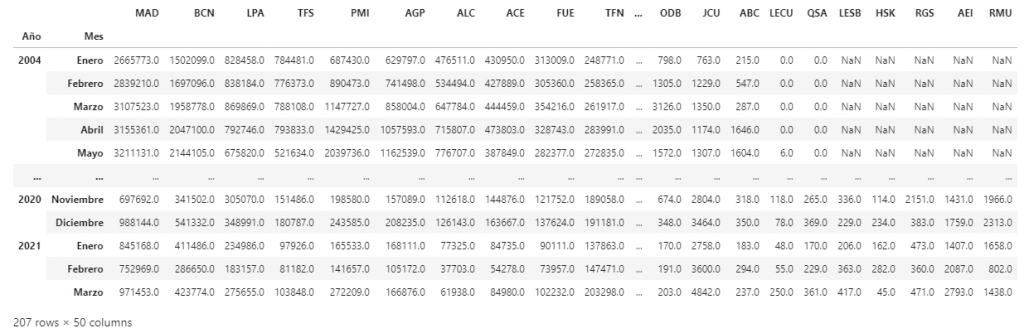
Resultado
El resultado de este artículo son tres dataframes, uno con los datos sobre pasajeros, otro sobre las operaciones realizadas y finalmente otro dataframe con información sobre carga en cada uno de los aeropuertos de España.
Líneas futuras
Esta sección recoge algunas de las tareas que quedan pendientes:
- Optimizar el código. Existe código duplicado que podría estructurarse en funciones de manera que sea más sencillo el mantenimiento del código.
- Añadir los dos scripts de actualización al Cron del sistema par que realmente se ejecuten mensualmente.
- Añadir un sistema de log y notificación que notifique de cualquier error o cambio en AENA con respecto a la estructura de datos, las URLs, etc.
- Funciones que permitan que extraer los datos facilmente.
- Crear un dashboard para por ejemplo monitorizar el tráfico aéreo en los aeropuertos vascos.