Extraer datos de Mercabilbao
Objetivo
El objetivo de este proyecto es extraer los datos estadísticos de la web de Mercabilbao y almacenarlos en una estructura de datos que permita un posterior acceso a los mismos sencillo e intuitivo. Para este proyecto será necesario el scraping de diferentes URLs que contienen tablas en formato HTML.
Ver código completo del proyecto en GitHub Mercabilbao
Desarrollo
Consideraciones previas:
El proceso de creación se ha realizado en dos pasos para por un lado, agilizar el proceso de scraping y además estructurar adecuadamente el dataframe.
Resumen de los pasos:
- Paso 1: Scrapear los datos de la web de Mercabilbao
- Paso 2: Ordenar los datos obtenidos en un dataframe multindex
Paso 1: Scrapear los datos de la web de Mercabilbao
Paso 1.1: Obtener todas las fechas en las que existen datos disponibles
El primer paso será obtener una lista con todos los años disponibles en la web de Mercadona.
url = 'http://www.mercabilbao.eus/servicios/estadisticas-de-productos/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
select_años = soup.findAll(id="sector-fecha")
años = select_años[0].findAll("option")
anos_disponibles = []
for elemento in años:
if (elemento['value'] != ""):
anos_disponibles.append(elemento['value'])Posteriormente, tendremos que obtener todas las semanas disponibles para cada año disponible. Esta información será recogida en un diccionario.
ano_semanas = {}
for ano in anos_disponibles:
url = "http://www.mercabilbao.eus/servicios/estadisticas-de-productos/?esttype=year&estyear-secundario=" + str(ano) + "&estyear=" + str(ano) + "&estweek=&estmonth=&estmarket=0#"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
select_semana = soup.findAll(id="selector-semana")
semanas = select_semana[0].findAll("option")
semanas_disponibles = []
for elemento in semanas:
if (elemento['value'] != ""):
semanas_disponibles.append(elemento['value'])
ano_semanas[str(ano)]= semanas_disponiblesY finalmente obtenemos un diccionario con la estructura de año-mes-día.
ano_mes_dia = {}
for ano in ano_semanas:
ano_mes_dia[ano] = {}
for semana in ano_semanas[str(ano)]:
ano_mes_dia[ano][str(semana.split('-')[0])] = []
for ano in ano_semanas:
for semana in ano_semanas[str(ano)]:
ano_mes_dia[ano][str(semana.split('-')[0])].append(str(semana.split('-')[1]))Paso 1.2: Obtener las tablas HTML en formato dataframe
En este paso el objetivo es almacenar para cada una de las semanas disponibles, las dos tablas HTML disponibles en un formato dataframe. Por lo que, el resultado será un dataframe con índices de año, mes, día y mercado el cual tendrá dos columnas (productos y origen) que almacenarán las tablas en formato dataframe.
Este paso permite que el proceso de scraping sea lo más rápido posible y dejar para un paso posterior la ordenación y limpieza de los datos.
raw_dataframe_productos = pd.DataFrame(columns = ['Año', "Mes", 'Semana', 'Mercado', 'Productos'])
for ano, semanas in ano_semanas.items():
for semana in semanas:
url= "http://www.mercabilbao.eus/servicios/estadisticas-de-productos/?esttype=week&estyear-secundario=" + ano + "&estyear=" + ano + "&estweek=" + semana + "&estmonth=&estmarket=0&estsend=Seleccionar#"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
select_mercado = soup.findAll(id="sector-mercado")
mercados = select_mercado[0].findAll("option")
for elemento in mercados:
if (elemento['value'] != ""):
mercado = elemento.text
url2 = "http://www.mercabilbao.eus/servicios/estadisticas-de-productos/?esttype=week&estyear-secundario=" + ano + "&estyear=" + ano + "&estweek=" + semana + "&estmonth=&estmarket=" + elemento['value'] + "&estsend=Seleccionar#"
response2 = requests.get(url2)
soup2 = BeautifulSoup(response2.text, 'html.parser')
productos_html = soup2.findAll("table", {"class": "stats"})
origen_html = soup2.findAll("table", {"class": "stats stats2"})
if (len(productos_html) > 1):
df_productos = pd.read_html(str(productos_html[0]),decimal=',', thousands='.')
productos = df_productos[0].set_index(['Producto'])
else:
productos = ""
if len(origen_html) > 0:
df_origen = pd.read_html(str(origen_html[0]),decimal=',', thousands='.')
origen = df_origen[0].set_index(['Origen'])
else :
origen = ""
row_df = pd.DataFrame([[ano, semana.split('-')[0], semana.split('-')[1], mercado, productos, origen]], columns = ['Año', "Mes", 'Semana', 'Mercado', 'Productos', 'Origen'])
raw_dataframe_productos = pd.concat([row_df, raw_dataframe_productos],ignore_index=True)
raw_dataframe_productos.set_index(['Año', "Mes", 'Semana','Mercado'], inplace=True)Como se puede observar en el script anterior, existe una función en Python/Pandas, read_html(), para transformar una tabla HTML en un Dataframe. A continuación un ejemplo de cómo se ha utilizado la función.
df_productos = pd.read_html(str(productos_html[0]),decimal=',', thousands='.')El último paso sería serializar el dataframe resultante.
pd.to_pickle(raw_dataframe_productos, "./raw_dataframe_productos.pkl")Paso 2: Ordenar los datos obtenidos en un dataframe multindex
El objetivo de este paso es estructurar el dataframe del paso anterior en otro en el que el acceso a la información sea posible de una forma intuitiva.
Paso 2.1: Obtener la estructura de año/mes/día disponibles
El primer paso será deserializar el dataframe obtenido en el paso anterior.
raw_dataframe_productos = pd.read_pickle("./raw_dataframe_productos.pkl")
raw_dataframe_productos = raw_dataframe_productos.reset_index()
raw_dataframe_productos.set_index(['Año', "Mes", 'Semana','Mercado'], inplace=True)El siguiente paso tiene como resultado principal un diccionario con la estructura de año/mes/día. IMPORTANTE. Esta última estructura, año/mes/día, será la que transformaremos en los índices de nuestro dataframe final.
df = raw_dataframe_productos.reset_index()
ano_mes_semana = {}
anos_disponibles = df["Año"].unique().tolist()
for ano in anos_disponibles:
meses_disponibles = df[df["Año"] == ano]["Mes"].unique().tolist()
ano_mes_semana[ano] = {}
for mes in meses_disponibles:
semanas_disponibles = df[(df["Año"] == ano) & (df["Mes"] == mes)]["Semana"].unique().tolist()
ano_mes_semana[ano][mes] = {}
for semana in semanas_disponibles:
ano_mes_semana[ano][mes][semana] = 0
Además, crearemos una lista con todos los mercados existentes.
mercados = df["Mercado"].unique().tolist()Paso 2.2: Obtener las estructuras básicas (de filas y columnas) del dataframe final
En este paso se obtendrán los productos para cada uno de los mercados así como los indicadores (kilos, precio máximo, etc.) para cada uno de los mercados.
productos = {}
indicadores = []
for ano in ano_mes_semana:
for mes in ano_mes_semana[ano]:
for semana in ano_mes_semana[ano][mes]:
for mercado in mercados:
productos[mercado] = []
a = df[(df["Año"] == ano) & (df["Mes"] == mes) & (df["Semana"] == semana) & (df["Mercado"] == mercado)]["Productos"].values[0]
if type(a) != str:
for elem in a.columns:
indicadores.append(elem)
for elemento in a.index.get_level_values("Producto").unique().tolist():
productos[mercado].append(elemento)En el siguiente paso, se eliminarán los productos duplicados para cada mercado, así como los indicadores duplicados.
for mercado in productos:
productos[mercado] = list(set(productos[mercado]))
indicadores = list(set(indicadores))Finalmente se creará un diccionario en el que se incluirá para cada producto de cada mercado la lista de indicadores.
productos_indicador = {}
for mercado in productos:
productos_indicador[mercado] = {}
for producto in productos[mercado]:
productos_indicador[mercado][producto] = {}
for ind in indicadores:
productos_indicador[mercado][producto][ind] = float('NaN')Paso 2.3: Fusionar las estructuras para crear la estructura del dataframe final
En este paso se transformarán los diccionarios en dataframes para posteriormente «fusionar» los dataframes. El primer dataframe serán los índices de las filas, y el segundo, serán las columnas de dicho dataframe final.
El siguiente código transforma un diccionario de tres niveles en un dataframe multindex.
reform = {(level1_key, level2_key, level3_key): values
for level1_key, level2_dict in ano_mes_semana.items()
for level2_key, level3_dict in level2_dict.items()
for level3_key, values in level3_dict.items()}
fechas_mercabilbao = pd.DataFrame(reform, index=[0]).TEl resultado del script anterior se puede observar en la siguiente imagen. Obsérvese que se le aplica la transposición al dataframe (.T)

reform2 = {(level1_key, level2_key, level3_key): values
for level1_key, level2_dict in productos_indicador.items()
for level2_key, level3_dict in level2_dict.items()
for level3_key, values in level3_dict.items()}
productos_mercabilbao = pd.DataFrame(reform2, index=[0])El script anterior da como resultado el siguiente dataframe.

Finalmente, solo queda crear un dataframe vacío pero con la estructura de los dos dataframes anteriores. A continuación el script y el resultado.
df2 = pd.DataFrame(productos_mercabilbao, index=fechas_mercabilbao.index)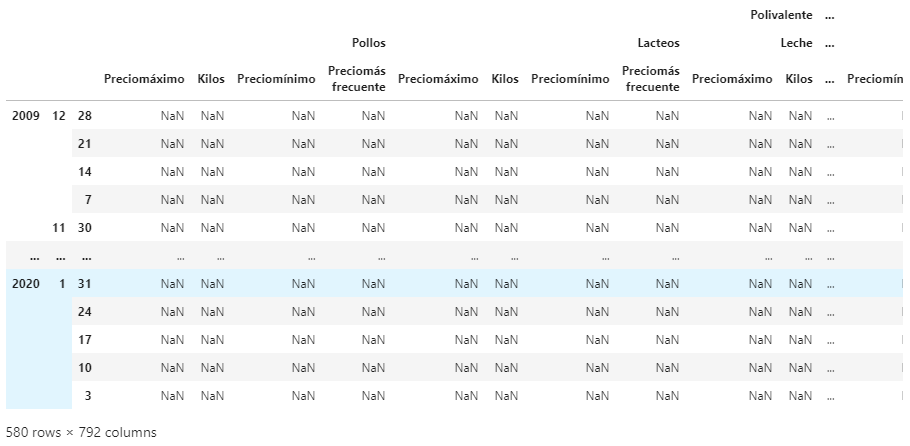
Paso 2.4: Rellenar los datos del dataframe
El siguiente script asigna a cada celda del dataframe anterior el valor del dataframe original.
df10 = df2.copy()
for ano in ano_mes_semana:
for mes in ano_mes_semana[ano]:
for semana in ano_mes_semana[ano][mes]:
for mercado in productos_indicador:
for producto in productos_indicador[mercado]:
for ind in productos_indicador[mercado][producto]:
XXX = df[(df["Año"] == ano) & (df["Mes"] == mes) & (df["Semana"] == semana) & (df["Mercado"] == mercado)]["Productos"].values[0]
if type(XXX) != str :
if producto in list(XXX.index):
df10.loc[(ano, mes, semana), (mercado,producto,ind)] = XXX.loc[producto][ind]
El resultado del anterior script se puede ver en la siguiente imagen.
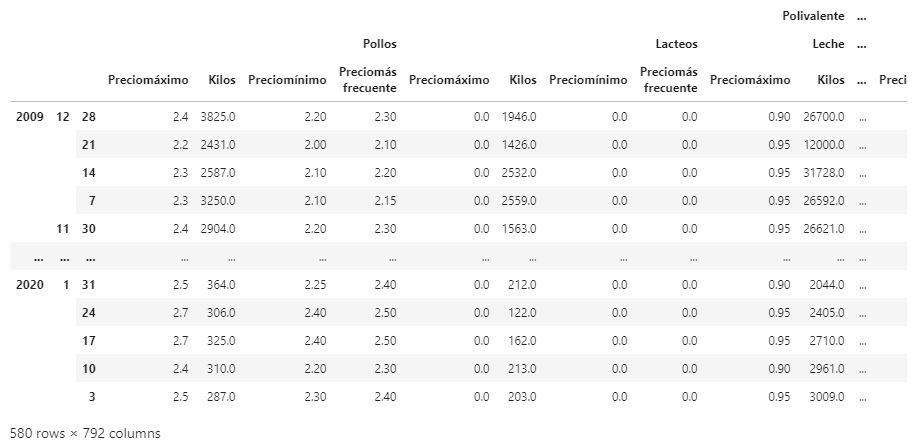
Resultado
El resultado es un dataframe multindex (deberían ser dos, ya que además del dataframe de productos faltaría el de origen) estructurado de forma lógica.
Líneas futuras
A este proyecto le faltarían dos elemntos principales:
- Desarrollar el mismo script para la información sobre el Origen de los productos.
- Desarrollar un actualizador del dataframe semanal.
- Desarrollar un conjunto de funciones para disponer de un fácil acceso a los datos. Se podría partir del siguiente script.